In a previous article we demonstrated how Excel responds when we try to load too many rows of data into an Excel worksheet. The problem is that a worksheet has a maximum of 1,048,576 rows and any additional data is truncated. Large datasets must then be loaded into multiple worksheets for analysis which can become a bit awkward.
Large datasets do not need to be loaded directly into an Excel worksheet anymore. We now have the ability to load datasets into the Excel Data Model without splitting the data into pieces. In this article we use Power Query to load our sample dataset from the previous article along with some larger versions. We will see that the Data Model has no trouble loading millions of rows of data, and is very efficient at handling large amounts of data.
We have a sample data file with 5 columns and 2,299,502 rows. As we demonstrated previously, loading this into an Excel worksheet will load just under half of the file. The file has a header row so including that the worksheet can hold 1,048,576 rows of the data file. In the current post we will load our sample data file into the Excel data model instead of a worksheet. The sample file can be downloaded here if you wish to experiment. The first 14 lines of the file can be seen in Fig. 1.
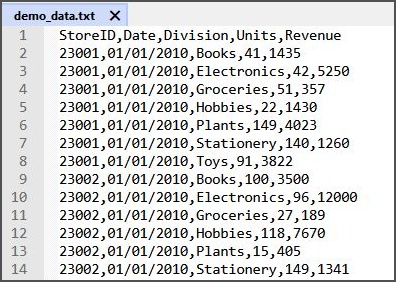
Fig. 1: First 14 lines of a sample data file.
We will use Excel’s Power Query tools to load the data – Power Query is found on the Data tab. In the Get & Transform Data group, select “Get Data” -> “From File” and click on “From Text/CSV” as shown in Fig. 2.
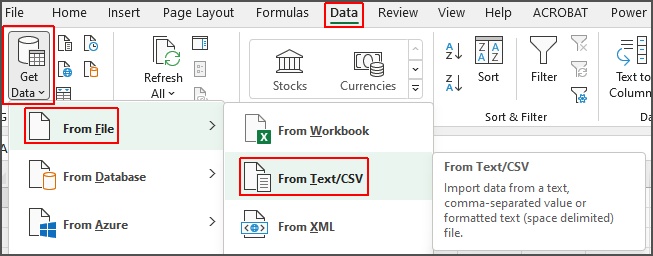
Fig. 2: The Power Query Text/CSV command.
This opens the Import Data file browser, which you can use to locate the file on your computer as shown in Fig. 3.
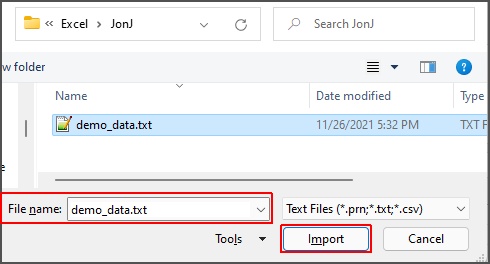
Fig. 3: Data Import file browser.
Once the file is selected, click the “Import” button to begin reading the file which opens the preview window of Fig. 4.
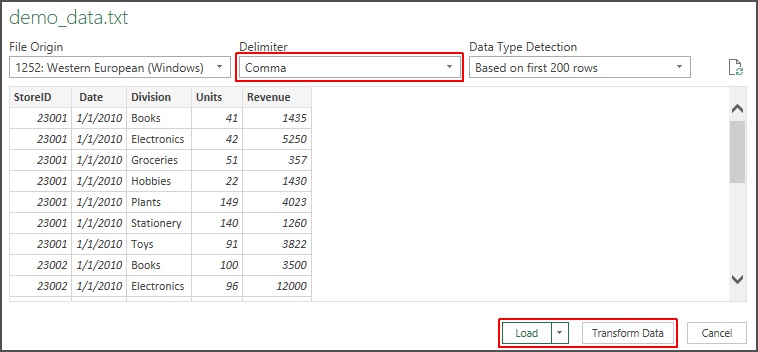
Fig. 4: Data import preview window.
The loader will guess about the organization of data in the file and show you the first lines – you have the opportunity to make adjustments, particularly if Excel has chosen an incorrect delimiter. You can choose the correct one or define the layout of a fixed width file if necessary.
Once the file is being read correctly you can either select the “Load” command of Fig. 5, which instructs Excel to load the data into a worksheet with no other changes, or the “Load To…” command which provides some options on what to do with the data.

Fig. 5: “Load” or “Load To …” options on the data import preview.
Selecting the “Load To…” command brings up the “Import Data” dialog box where we can add the data to the Excel Data Model. We select “Only Create Connection”, and the checkbox to “Add this data to the Data Model”. When we only create a connection to the data, the data isn’t loaded into a table or worksheet, only information about the connection is saved. For example, if we create a connection to load data from a text file, Excel will save the full path to the data file, along with perhaps some preview information about the file. Database connections will require a bit more information, but no actual data will be loaded. This connection information is contained in M language code generated by Power Query as we fill in the connection information.
When we choose to “Add this data to the Data Model”, as shown in Fig. 6, the data are read into Excel, but not loaded to a worksheet. Data loaded into the Data Model are saved in the Excel file. From here we can work with the entire dataset, or multiple datasets, beyond the traditional maximum size, for analysis. Also, since the data is saved with the connections, we can always come back later and refresh the data with any new changes and continue with analysis.
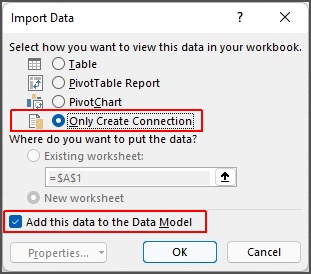
Fig. 6: Choosing where to load the data.
Excel does an excellent job of compressing the data we load to the Data Model as we see in Fig. 7.

Fig. 7: Comparison of compression by WinRAR Zip and Excel Data Model
We have 3 sample data files ranging from over 2 million rows to almost 15 million rows. The smallest sample data file can be downloaded here. The larger files have the same column structure as the smallest, just with more rows. Again, the column structure of the files is the same as that shown in Fig. 1. Note that commas are used as delimiters so the filename could equivalently use a .csv extension.
The largest uncompressed text file requires 491 MB of storage. When we use WinRAR’s normal zip compression, the compressed file requires just over 80 MB of storage space. Loading the full data file into Excel’s Data Model and saving the Excel file results in a file size of 33.7 MB. We see that the zip algorithm has compressed the file by just over a factor of 6, while Excel’s Data Model compression has reduced the required size for storage by over a factor of 14. This pattern holds for all three sample data files, which makes sense because the column structures of the data are the same, the only variation is the number of rows.
The time that it takes for Excel to load data into the Data Model will vary a great deal depending on the number of columns, data types of the columns and of course, the number of rows. To complete our example, Fig. 8 shows the times for Excel to load the datasets into the Data Model.
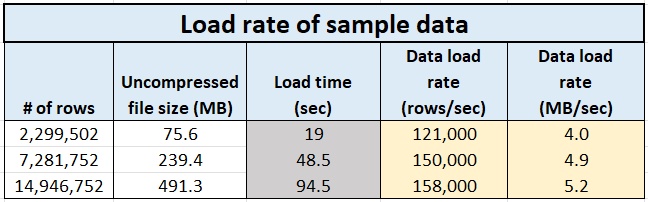
Fig. 8: Time to load the datasets
For our sample data, Excel is loading the files at between 120 and 160 thousand rows per second. This will vary greatly when rows are longer. We also see that Excel is loading the data at a rate of 4 to 5 MB/s, and perhaps this will be a bit less variable, but would need to be tested with your own data. The rate of loading data will depend on both the nature of the dataset, and the hardware used to work with that data. There are links above to download our small sample dataset if you would like to compare your computer’s performance.
The Data Model provides Excel with the ability to effectively handle large datasets on our desktop computers. This gives Excel users the power to provide analysis of many large datasets without the need for specialized equipment. The Data Model is a very empowering addition for everyone who uses Excel for data analysis, allowing us to load and store large volumes of data quickly. Future articles will discuss how we work with data in the Data Model.
{kind=link}
{kind=link}
Leave A Comment